Cómo utilizar la IA para Analizar y Visualizar Datos: Un caso práctico con Remesas en Nicaragua

Por Romero & Ordóñez
Introducción
La inteligencia artificial (IA) se ha convertido en una herramienta poderosa para analizar grandes volúmenes de datos y extraer información valiosa. En este artículo, detallaremos el proceso paso a paso seguido al interactuar con un asistente de IA (en este caso, Gemini integrado en Google Colab) para analizar un conjunto de datos de remesas mensuales de Nicaragua y generar la visualización más adecuada. El objetivo era simple: obtener la mejor gráfica posible a partir del archivo descargado del sitio web del BCN: https://www.bcn.gob.ni/base-de-datos-estadisticos.
1. La solicitud inicial
El proceso comenzó con una petición directa al asistente de IA: "Elabora la gráfica más apropiada y la que más se ajuste a los datos", proporcionando el nombre del archivo Excel (1a.2.1.04.xls).
2. El plan de acción de la IA
El asistente propuso un plan estructurado para abordar la solicitud:
- Carga de datos: Cargar el archivo Excel en una estructura manipulable (Pandas DataFrame).
- Exploración de datos: Examinar tipos de datos, valores faltantes, distribuciones y estructura general.
- Visualización de datos: Crear diferentes tipos de gráficos basados en la exploración y seleccionar el más adecuado.
- Análisis de datos: Profundizar en los datos a través de la visualización elegida para identificar tendencias y patrones clave.
- Tarea finalizada: Presentar la visualización final, justificar su elección y resumir los hallazgos.
3. Ejecución del plan: un proceso iterativo
La ejecución del plan no fue lineal y requirió varias correcciones, lo que es común al trabajar con datos del mundo real.
Paso 1: Carga de datos y limpieza inicial
- Intento 1: Se cargó el archivo Excel directamente. La vista previa (df.head()) mostró que las primeras filas contenían encabezados múltiples y metadatos, no los datos en sí, resultando en muchas celdas NaN (Not a Number).
- Corrección 1: Se volvió a cargar el archivo especificando que el encabezado real comenzaba en la cuarta fila (header=3) y se eliminó una fila vacía (df.drop(index=4)). Sin embargo, las columnas aún tenían nombres genéricos ("Unnamed: X") y el índice no era significativo.
- Corrección 2: Se renombraron las columnas con nombres descriptivos ('Año', 'Ene', 'Feb', ..., 'Total'), se estableció la columna 'Año' como el índice del DataFrame (df.set_index('Año')) y se eliminaron filas completamente vacías (df.dropna(how='all')). Ahora, el DataFrame tenía una estructura limpia y lista para la exploración.
Paso 2: Exploración de datos y corrección de tipos
- Intento 1: Se intentó calcular estadísticas descriptivas y generar histogramas y un mapa de calor de correlación. Esto falló con un ValueError, indicando que no se podían describir columnas no numéricas. La revisión (df.dtypes) confirmó que todas las columnas de meses eran de tipo 'object' (texto) en lugar de numéricas.
- Corrección: Se aplicó una conversión explícita para transformar las columnas de meses a tipo numérico, usando pd.to_numeric con errors='coerce' (que convierte los valores no numéricos en NaN). Tras esto, se pudo:
- Calcular estadísticas descriptivas (media, desviación estándar, mínimo, máximo, etc.) para cada mes y el total anual.
- Visualizar la distribución de los datos mensuales mediante histogramas.
- Generar un mapa de calor de correlación, que mostró una fuerte correlación positiva entre los montos de remesas de diferentes meses.
- Evaluar los valores faltantes (NaN) introducidos durante la conversión, observando que algunos meses tenían hasta un 8% de datos faltantes.
Paso 3: Visualización de datos y ajuste final
- Intento 1: Se intentó crear un gráfico de líneas y uno de barras para visualizar la columna 'Total' anual a lo largo de los años (el índice 'Año'). Esto generó un TypeError porque la función de trazado esperaba que los valores del eje X (los años) fueran de tipo texto (string), pero aún eran numéricos.
- Corrección: Se convirtió el índice 'Año' a tipo texto (df.index = df.index.astype(str)). Con esta corrección, se generaron exitosamente:
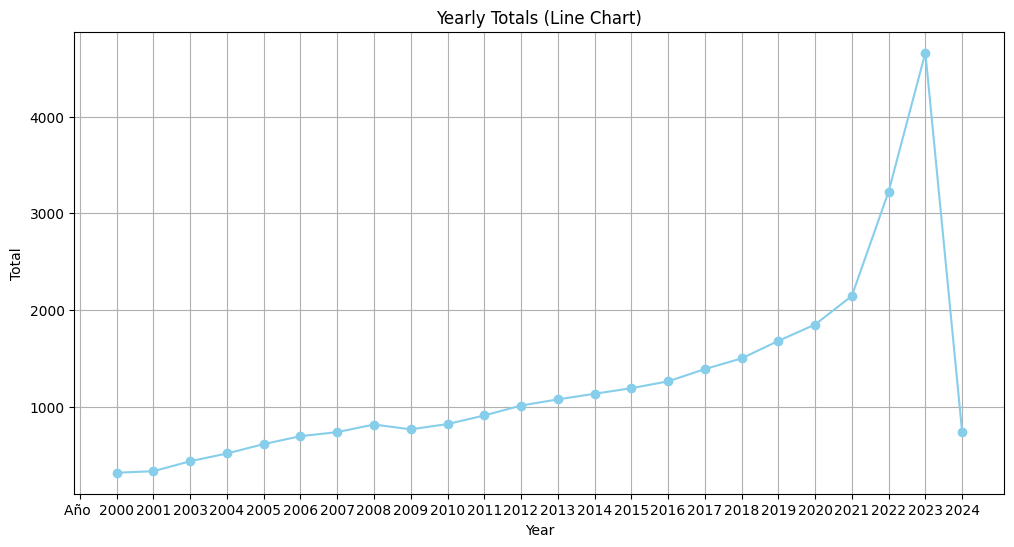
- Un gráfico de líneas mostrando la evolución del total anual de remesas.
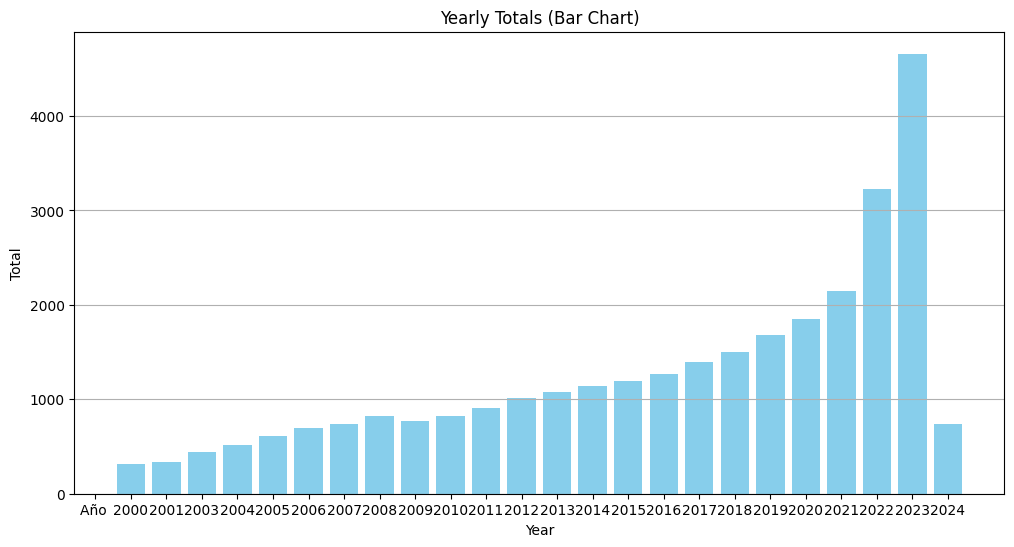
- Un gráfico de barras comparando la magnitud del total anual de remesas para cada año.
- Evaluación: Se compararon ambos gráficos. Se concluyó que el gráfico de líneas era ligeramente superior para mostrar la tendencia y el crecimiento a lo largo del tiempo, mientras que el gráfico de barras enfatizaba mejor la magnitud en cada año específico.
Paso 4: Análisis de datos
- Se calcularon estadísticas clave para la columna 'Total' anual.
- Se calculó la tasa de crecimiento porcentual anual promedio.
- Se identificaron los años con el total de remesas más alto y más bajo registrados en el dataset.
4. Resultados finales y conclusiones del análisis
Basado en el proceso anterior, se generó el siguiente:
¿Cuál es la visualización más apropiada y por qué?
- Se considera que un gráfico de líneas es el más apropiado. La razón principal es la significativa tasa de crecimiento anual promedio (9.34%), que este tipo de gráfico visualiza eficazmente como una tendencia a lo largo del tiempo. Además, la alta desviación estándar (975.84) indica una volatilidad considerable, que también es bien representada por las fluctuaciones en un gráfico de líneas.
Hallazgos clave del análisis de datos:
- Tasa de crecimiento anual promedio: Los totales anuales muestran un crecimiento promedio positivo del 9.34%.
- Volatilidad de los datos: La desviación estándar de los totales anuales es alta (975.84), indicando una variabilidad sustancial en los montos año tras año.
- Valores extremos: El total anual más alto (4660.1 millones de dólares) se observó en 2023, mientras que el más bajo (320.0 millones de dólares) ocurrió en 2000.
Conclusión
Este caso práctico demuestra cómo la interacción con una IA puede facilitar el análisis y la visualización de datos. Es importante destacar que el proceso a menudo es iterativo, requiriendo ajustes y correcciones basadas en los errores encontrados y la comprensión progresiva de los datos, pero todo hecho por sí solo por el agente. Al final, se logró obtener una visualización clara (el gráfico de líneas) que responde efectivamente a la solicitud inicial, junto con un análisis cuantitativo que proporciona información valiosa sobre las tendencias de las remesas.